国产(AI,算力芯片全景图)
自主可控受高度重视,高水平科技亟需自立自强。国务院在“两会“期间组建国家数据局,负责统筹推进数字经济发展、推进数据基础设施布局建设等任务,有望加速推进数字中国建设落地;国务院重组科技部,并组建中央科技委员会,亦有望加速推动国内高水平科技实现自立自强。AI 算力芯片作为数字中国的算力基础,国产突破势在必行,国产 AI 算力芯片迎来发展”芯“机遇。
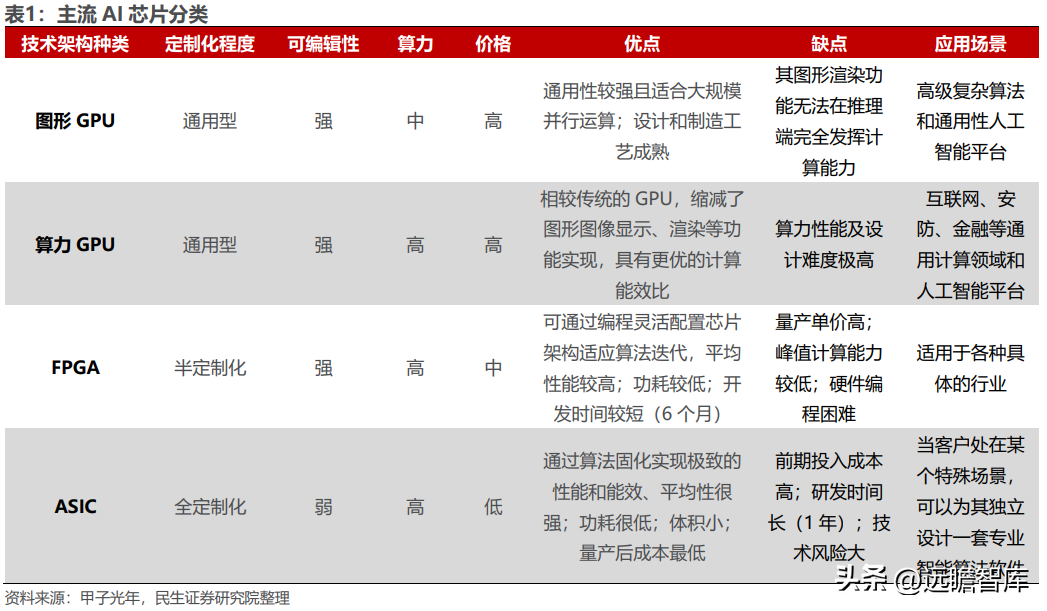
AI 芯片赋能算力基石,英伟达垄断全球市场。AI 算力芯片主要包括 GPU、FPGA,以及以 VPU、TPU 为代表的 ASIC 芯片。其中以 GPU 用量最大,据 IDC 数据,预计到 2025 年 GPU 仍将占据 AI 芯片 8 成市场份额。然而,相较传统图形 GPU,通用型算力 GPU 在芯片架构上缩减了图形图像显示、渲染等功能实现,具有更优的计算能效比,因而被广泛应用于人工智能模型训练、推理领域。
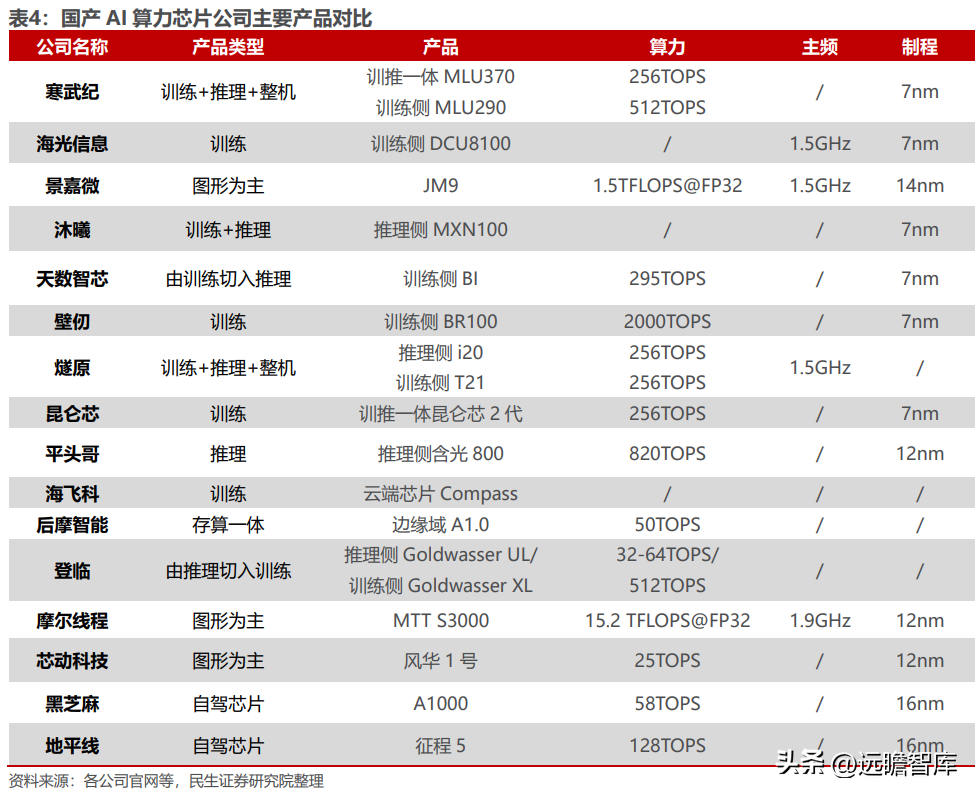
全球 AI 芯片市场被英伟达垄断,然而国产 AI 算力芯片正起星星之火。目前,国内已涌现出了如寒武纪、海光信息等优质的 AI 算力芯片上市公司,非上市 AI 算力芯片公司如沐曦、天数智芯、壁仞科技等亦在产品端有持续突破。
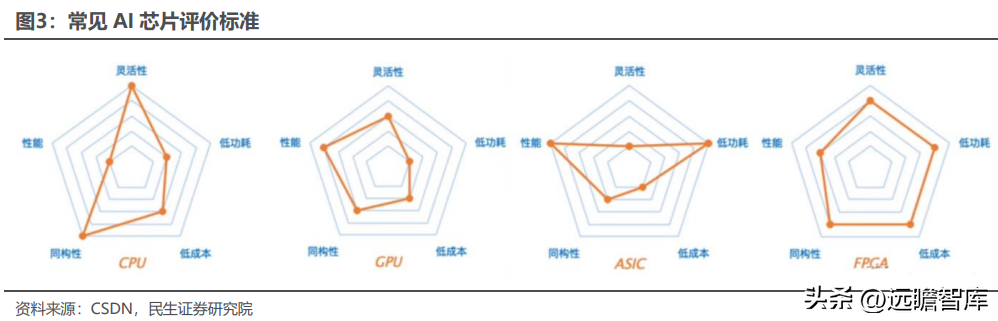
评价 AI 芯片的指标主要包括算力、功耗、面积、精度、可扩展性等,其中算力、功耗、面积(PPA)是评价 AI 芯片性能的核心指标:
国务院组建国家数据局、重组科技部,结合前期数字中国建设规划落地、浪潮集团被美国商务部列入”实体清单“等事件,我们认为,国产 AI 算力芯片迎来发展“芯“机遇,自主可控亟待加速。
以上内容仅供学习交流,不构成投资建议。详情参阅原报告。
数字中国建设对 AI 芯片国产化提出新要求。中央印发了《数字中国建设整体布局规划》。《规划》提出要夯实数字基础设施和数据资源体系“两大基础”,我们认为,数字中国基础设施的建设有望拉动以数据中心、超算中心、智能计算中心为代表的算力基础设施建设,从而带动服务器与 AI 算力芯片的需求快速增长。同时,《规划》提出要构筑自立自强的数字技术创新体系,上游 AI 芯片作为算力基础,自主可控需求凸显,数字中国建设对 AI 芯片国产化提出新要求。

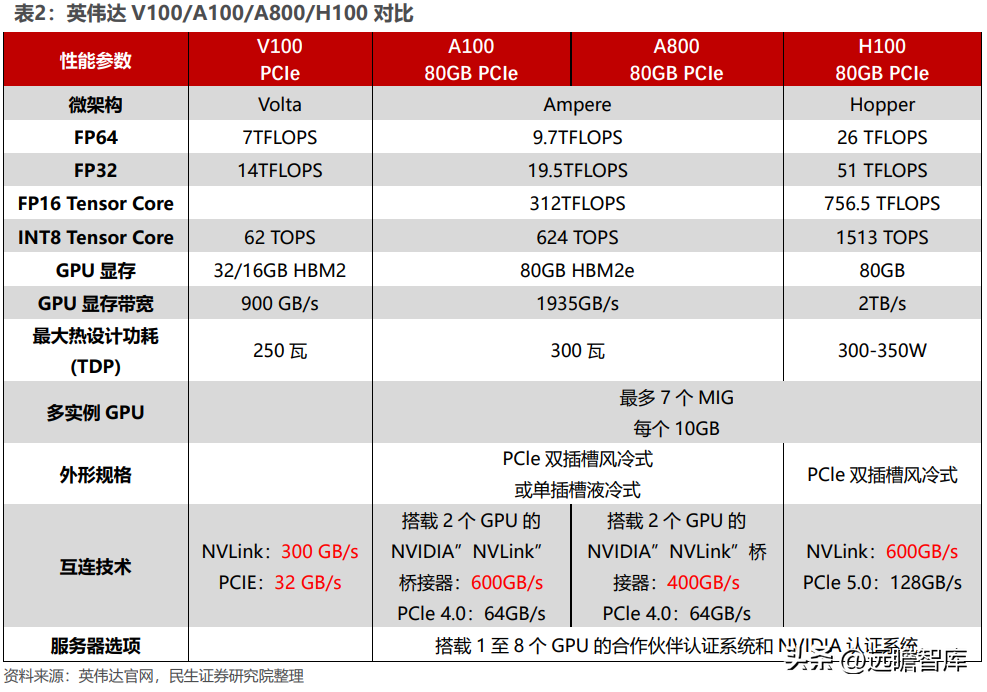
英伟达的 GPGPU 是全球应用最为广泛的 AI 芯片,决定其性能的硬件参数主要包括:微架构、制程、CUDA 核数、Tensor 核数、频率、显存容量、显存带宽等。其中,微架构即 GPU 的硬件电路设计构造的方式,不同的微架构决定了 GPU的不同性能,作为英伟达 GPU 的典型代表,V100、A100、H100 GPU 分别采用Volta、Ampere、Hopper 架构;CUDA 核是 GPU 内部主要的计算单元;Tensor核是进行张量核加速、卷积和递归神经网络加速的计算单元;显存容量和带宽是决定 GPU 与存储器数据交互速度的重要指标。
(报告作者:民生证券研究所分析师 方竞)
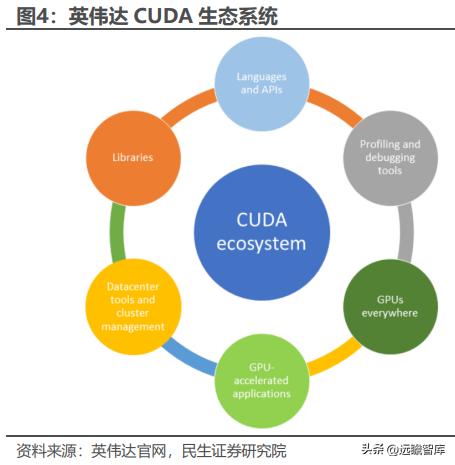
除 GPU 硬件之外,与之配套的软件开发体系亦是生态的重要组成部分。GPU的生态包括底层硬件、指令集架构、编译器、API、基础库、顶层算法框架和模型等,英伟达于 2006 年发布的 CUDA 平台是当今全球应用最为广泛的 AI 开发生态系统。通用 GPU 与 CUDA 组成的软硬件底座构成了英伟达引领 AI 计算的根基,当前全球主流深度学习框架均使用 CUDA 平台。
根据在网络中的位置,AI 芯片可以分为云端 AI 芯片 、边缘和终端 AI 芯片;根据其在实践中的目标,可分为训练( training )芯片和推理( inference )芯片。云端主要部署高算力的 AI 训练芯片和推理芯片,承担训练和推理任务,具体有智能数据分析、模型训练任务和部分对传输带宽要求比高的推理任务;边缘和终端主要部署推理芯片,承担推理任务,需要独立完成数据收集、环境感知、人机交互及部分推理决策控制任务。
(3)面积:芯片的面积是成本的决定性因素之一,通常来讲相同工艺制程之下,芯片面积越小良率越高,则芯片成本越低。此外,单位芯片面积能提供的算力大小亦是衡量 AI 芯片成本的关键指标之一。
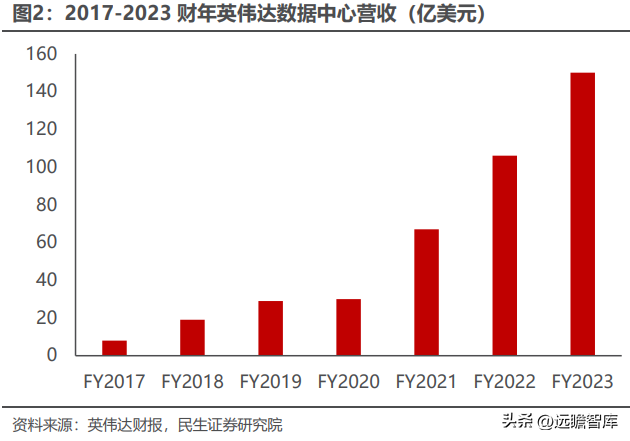
由于英伟达 GPU 产品线丰富、产品性能顶尖、开发生态成熟,目前全球 AI 算力芯片市场仍由英伟达垄断。根据中国信通院的数据,2021 年 Q4 英伟达占据了全球 95.7%的 GPU 算力芯片市场份额,因此,英伟达数据中心业务营收增速可以较好地反应全球 AI 芯片市场增速。2023 财年,英伟达数据中心营收达到 150 亿美元,同比增长 41%,FY2017-FY2023 复合增速达 63%,表明全球 AI 芯片市场规模保持高速增长。
浪潮集团被列入“实体清单“,AI 芯片国产化进程有望加速。当地时间 3 月2 日,美国商务部将浪潮集团、龙芯中科等 37 个实体列入“实体清单“,扩大对浪潮等中国企业的出口禁令。浪潮集团等公司被列入“实体清单”,再度敲响了中国 AI 产业发展的警钟,我们不但要加大数字基础设施建设,AI 算力芯片的自主可控推进也势在必行。
(1)算力:衡量 AI 芯片算力大小的常用单位为 TOPS 或者 TFLOS,两者分别代表芯片每秒能进行多少万亿次定点运算和浮点运算,运算数据的类型通常有整型 8 比特(INT8)、单精度 32 比特(FP32)等。AI 芯片的算力越高,代表它的运算速度越快、性能越强。

(2)功耗:功耗即芯片运行所需的功率,除了功耗本身,性能功耗比是综合衡量芯片算力和功耗的关键指标,它代表每瓦功耗对应输出算力的大小。
除 PPA 之外,运行在 AI 芯片上的算法输出精度、AI 应用部署的可扩展性与灵活性,均为衡量 AI 芯片性能的指标。
根据芯片的类别,AI 算力芯片主要包括 GPU、FPGA,以及以 TPU、VPU 为代表的 ASIC 芯片,其中以 GPU 用量最大,据 IDC 数据,预计到 2025 年 GPU 仍将占据 AI 芯片 8 成市场份额。

生态构建计算壁垒,国产 GPU 厂商初期兼容 CUDA,长期仍需构筑自身软硬件生态。由于当前全球主流深度学习框架均使用 CUDA 平台进行开发,国产 GPU可以通过兼容 CUDA 的部分功能,快速打开市场,减少开发难度和用户移植成本。然而,CUDA 本身涵盖功能非常广泛,且许多功能与英伟达 GPU 硬件深度耦合,包含了许多英伟达 GPU 的专有特性,这些特性并不能在国产 AI 芯片上全部体现。因此,长期来看国产 GPU 厂商仍需通过提升自身的软硬件实力,构筑属于自己的软硬件生态。
海森药业跌停,上榜营业部合计净卖出1099.30万元
海森药业今日跌停,全天换手率35.98%,成交额3.50亿元,振幅9.89%。龙虎榜数据显示,营业部席位合计净卖出1099.30万元。深交所公开信息显示,当日该股因日换手率达35.98%、日跌幅偏离值达-10.20%上榜,营业部席位合计净卖出1099.30万元。0000当之无愧的电车之王,特斯拉!
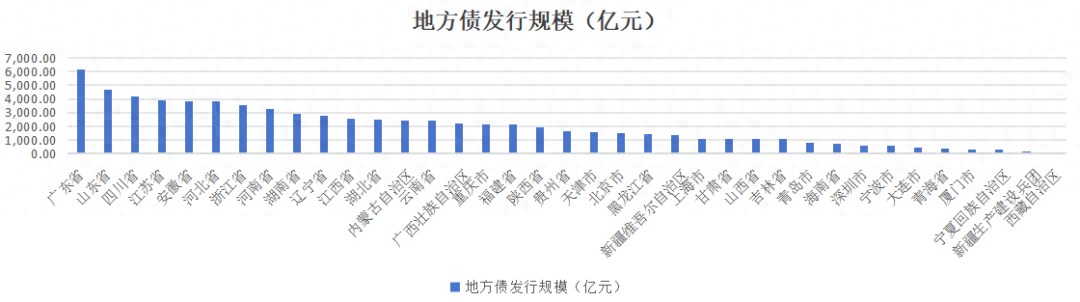
大财经2023-12-28 10:31:5400002023年江苏省地方政府债券分析报告
大财经2023-11-29 18:20:4500017有关雪的诗句 雪的诗句发朋友圈
多地初雪已至,我们为大家准备了100句关于雪的诗、词、文,就在赏雪中领略诗人那浓浓的雪中情意吧。1、何时杖尔看南雪,我与梅花两白头。——查辛香《清稗类钞·咏罗浮藤杖所作》2、晚来天欲雪,能饮一杯无?——白居易《问刘十九》3、昔去雪如花,今来花似雪。——范云《别诗》4、柴门闻犬吠,风雪夜归人。——刘长卿《逢雪宿芙蓉山主人》5、忽如一夜春风来,千树万树梨花开。——岑参《白雪歌送武判官归京》0000在上海·圆桌派(专刊):中国需求复苏,外资如何把握市场机遇
大财经2023-04-30 07:40:100000