AES发电(AES.US)收购加州大型太阳能发电厂开发项目
大财经2024-01-09 15:52:121阅
智通财经APP获悉,美国AES发电(AES.US)正在收购加州一座在建的大型太阳能发电厂。
AES发电从太阳能开发商Avantus LLC手中收购了位于克恩县的贝尔菲尔德太阳能发电厂和储能项目。这个2千兆瓦的项目将为150万加州家庭提供足够的电力,并将于2025年开始向电网供电。
交易的财务条款没有披露。
去年的《减少通货膨胀法案》提供了激励措施,以帮助推动美国在2035年之前生产100%的清洁电力。这促使开发商越来越多地建设带有储能的可再生能源项目,以减轻美国电网的压力,同时让企业全天候使用零碳能源。
AES首席执行官Andrsamus Gluski表示,“我们必须努力实现这些目标;这并不容易,”他表示,今天宣布的协议是朝着这个方向迈出的“极其重要”的一步。
0001
相关推荐
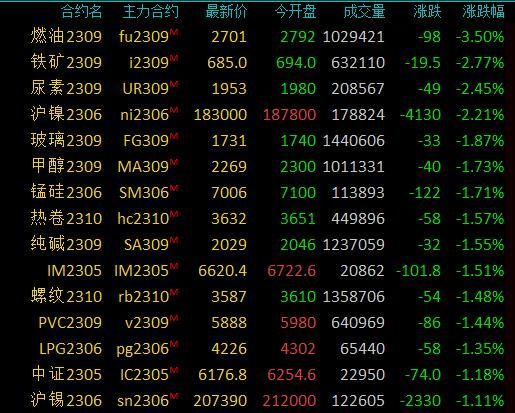
商品期货早盘收盘多数下跌,燃料油跌超3%,铁矿石、尿素、沪镍跌超2%
金融界5月5日消息国内期货市场早盘收盘,商品期货多数下跌,棕榈油涨近3%,菜油、豆一、棉花、棉纱、沪银、豆油涨超1%。跌幅方面,燃料油跌超3%,铁矿石、尿素、沪镍跌超2%,甲醇、玻璃、锰硅跌近2%。黑色系持续下挫,铁矿石今日跌3%,价格创5个月新低;螺纹、热卷价格也跌至2023年新低。大财经2023-05-06 10:00:010000快餐和奶茶将激烈争夺加盟商 | 界面预言家㉓
界面新闻记者|吴容界面新闻编辑|牙韩翔在消费餐饮行业过去存在着这样一个鄙视链——做直营的瞧不起加盟的。大部分餐饮创业似乎更希望自己开创一个品牌,然后通过直营的模式进行扩张。但最近几年,加盟模式却在以一种前所未有的声势,最大程度地拥抱消费者。更多的餐饮品牌在2023年选择开放了加盟模式,希望以更轻的形式进行扩张。大财经2024-01-03 15:07:550000关注|退休后能领多少养老金? 电子社保卡就能算!
电子社保卡官方APP电子社保卡支付宝小程序除了电子社保卡官方APP、微信小程序和支付宝小程序,国家政务服务平台、国务院客户端微信小程序、掌上12333、云闪付、人社部门APP、服务银行APP等渠道均可申领电子社保卡哦~来源:社会保障卡微信号本期编辑:于芊芊大财经2023-05-27 13:51:540000冀中能源股份公司云驾岭矿奏响节支降耗“最强音”
【来源:河北省国有资产监督管理委员会_国资运营】面对持续下行的市场形势,云驾岭矿牢固树立过紧日子思想,在节支降耗上大做文章,实施全员抓节约,人人算细账、处处控成本,从“指缝间”抠出了“大效益”。前8个月,通过自主修旧利废、回收复用、内部调剂等措施创效800余万元。0000退休时可以一次性领取企业年金吗?1分钟看懂!
企业年金是指企业及其职工在依法参加基本养老保险的基础上,自主建立的补充养老保险制度。退休时可以一次性领取企业年金吗?1分钟带你看懂企业年金允许参保人员在退休时选择一次性领取职工在达到国家规定的退休年龄时,可以从本人企业年金个人账户中按月、分次或者一次性领取企业年金,也可以将本人企业年金个人账户资金全部或者部分购买商业养老保险产品,依据保险合同领取待遇并享受相应的继承权。大财经2023-04-29 22:27:270000