许家印真是害人不浅,越抓人,越辟谣,排队取钱的人就越多
恒大集团的债务危机引发了社会的广泛关注,特别是在近期流传的“恒大所欠银行贷款明细列表”引发了一波恐慌。人们纷纷涌入银行提取存款,对未来可能出现的不利事件或结果充满担忧。在这个情境下,我们需要关注人们的心理态度和风险偏好,以更好地理解他们的行为和选择。

首先,让我们了解一下风险偏好。风险偏好是指个体或投资者在面临不同投资或决策选择时,更倾向于选择潜在收益高于潜在损失的程度。风险偏好可以有很大的个体差异,它涉及到个体对风险的认知和评估,以及个体对不同风险和收益的主观感受。

影响人们对风险偏好的因素多种多样。以下是一些主要因素:
a. 风险与不确定性:人们通常更喜欢确定性,而不喜欢不确定性。即使在不确定性下可能出现更好的结果,他们更倾向于选择已知的、相对确定的选项。

b. 风险与潜在损失:人们倾向于过度关注潜在的损失,这一心理现象被称为“损失厌恶”。他们更关心可能失去的东西,而忽视了可能获得的好处。
c. 风险与控制感:拥有一定的控制感可以增强人的自信和安全感。然而,风险事件通常超出了个体的控制范围,这可能导致焦虑和担忧。

d. 风险与社会文化规范:社会文化规范对风险偏好也有影响。某些文化强调谨慎和规避风险,而其他文化可能更加开放和接受风险。
除了上述因素,还有其他一些因素可能影响个体的风险偏好,如认知偏差、情绪状态、动机类型、人格特征和经济状况等。每个人的背景和经历都会在某种程度上影响他们对风险的看法和反应。
在面对风险时,人们应该如何应对呢?
首先,客观理性地评估风险是非常重要的。这包括了解风险的大小、可能的损失程度以及潜在的回报。通过对风险进行合理的评估,个体可以更好地做出决策,选择适合自己的选项。
其次,个体应该根据自身的能力和目标来做出选择。不同人具有不同的风险承受能力,这可能受到个体的财务状况、家庭状况和职业等因素的影响。因此,每个人都应该根据自己的实际情况来决定是否承受特定的风险。
最后,教育和信息也是应对风险的关键因素。了解和理解不同类型的风险,以及如何减轻或规避这些风险,对于做出明智的决策至关重要。人们可以通过咨询专业人士、学习相关领域的知识以及谨慎研究市场趋势来提高自己的风险认知水平。
总之,恒大集团的债务危机引发了社会对风险的关注,而人们的风险偏好受多种因素影响。面对风险,客观理性地评估风险、根据自身能力和目标选择,以及积极获取相关信息都是应对风险的有效方法。希望人们能够理性看待风险,做出明智的决策。
多家航运公司宣布:暂停!
多家集装箱航运公司暂停在红海航行。12月16日,全球第三大集装箱航运公司达飞海运集团发布声明称,由于对红海及附近海域安全局势的担忧加剧,该集团宣布暂停其所有经红海的集装箱运输,直至另行通知。此外,据路透社15日报道,全球最大的集装箱航运公司马士基也暂停了所有通过连接红海和亚丁湾的曼德海峡的船只航行,直至另行通知。德国船运商赫伯罗特公司15日也宣布,暂停其集装箱船在红海的航行,直到12月18日。大财经2023-12-18 11:38:310000现代军事小说 男主是特殊部队军人的小说
大家好这里是大白推书给大家整理一下值得一读的军事小说汇总大白自行分级仅供参考以下链接为分级说明大白推书分级说明PS:因为是个人收集整理,力有不逮,没有那么全面,肯定会有遗漏,欢迎大家在留言区补充推荐。本次收录值得一读的军事共四十八本。军事小说分类分为战争幻想、特种军旅、现代战争、穿越战争、谍战特工、抗战烽火、军旅生涯等等。大财经2023-03-25 13:22:3900018高效能人士的七个习惯
这个世界上唯一公平的就是时间:马云一天是24小时,你我也是。大家有没有发现,有时候一直在忙碌,搞得自己很疲惫,却没有得到想要的结果?这其实在于我们对时间的利用程度,以及产出的”效能“多少。那么我们到底该怎么做,才能在有限的生命和时间里创造更多,获得更多呢?今天的分享,告诉你答案,建议收藏学习![赞]领取方式见文末大财经2023-03-21 13:32:230000甲状腺弥漫性肿大 甲状腺肿大会自愈吗
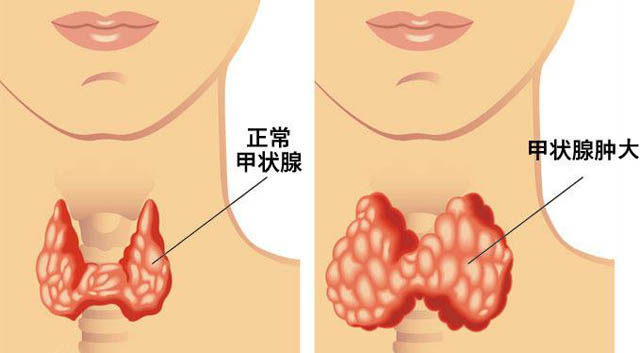
前文《什么是甲亢》中已经介绍了甲状腺肿大可以引起甲状腺功能亢进症(甲亢),本文就详细介绍甲状腺肿大的相关医学知识。甲状腺肿是指非炎症或肿瘤原因引起的甲状腺滤泡上皮细胞异常增生导致甲状腺肿大。分为非毒性甲状腺肿和毒性甲状腺肿。甲状腺肿是一种较常见的甲状腺疾病,女性发病率明显高于男性,特别是绝经前女性。其中,弥漫性非毒性甲状腺肿女性发病率是男性3~5倍。图片来自网络大财经2023-03-24 00:35:110000笑傲江湖结局 新版笑傲江湖结局
在陈乔恩和霍建华版本的《笑傲江湖》中,东方不败和令狐冲有一段感情纠葛!在李连杰和林青霞版本的《笑傲江湖之东方不败》中,两人不但暧昧,还有一夜风流,这些都是改编过后的,在原著中的东方教主,真正爱的,其实另有其人。而这个男人就是——杨莲亭。杨莲亭在原著中只是一个不起眼的小角色,但是他的一举一动却能牵动东方不败的心神。大财经2023-03-24 22:21:180001